
Experiments yield valuable information for creation of new production-ready, flexible shell around our anycast infrastructure
Since early 2020, we’ve been running a BGP anycast testbed at SIDN Labs. The purpose of the project is to investigate ways of making a global anycast infrastructure more cost-effective and flexible. We believe that cost-effectiveness could be improved if we didn’t have to physically ship servers around the world. And we want added flexibility so that we can be more agile in response to changing circumstances. Our ultimate goal is to develop the system to the production level, so that we have a ‘flexible shell’ around our existing anycast DNS infrastructure for .nl. This blog post provides an update on where we are with the project nearly a year on from the launch.
About anycast
Anycast is a tested means of increasing the resilience and performance of internet infrastructures. The principle is simple: the same IP address is given to multiple servers at multiple locations, with the result that the internet’s routing system automatically distributes the traffic load across the various servers. That reduces response times and thus improves the user experience. A query from a user in the Netherlands is routed to a server in Amsterdam, while someone in Japan has their query handled by a server in Tokyo. Anycast also improves the management of load peaks, such as occur during a DDoS attack.
Anycast technology is based on the Border Gateway Protocol (BGP), the internet’s routing protocol. The BGP ensures that internet traffic always takes the quickest route from A to B, which is usually also the shortest (see Figure 1).
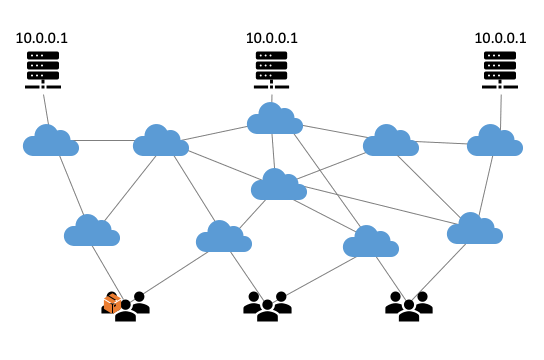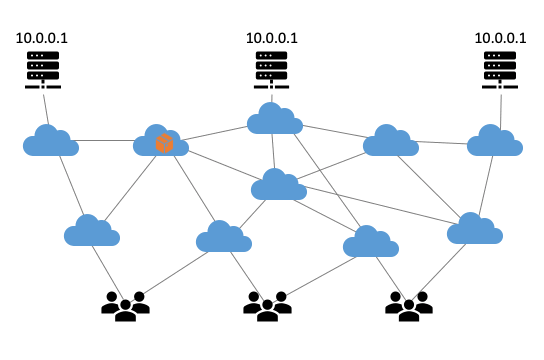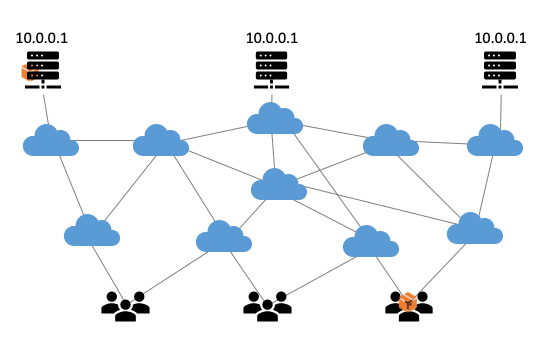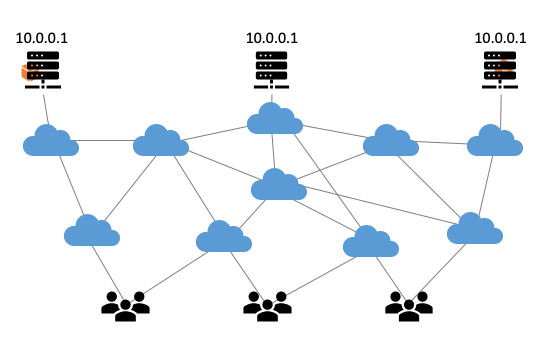
Figure 1: Visualisation of how anycast works.
Anycast has proven itself in practice. Indeed, we use anycast ourselves for .nl’s DNS infrastructure. And we are by no means unique in that respect; anycast is also used by a number of fellow registries, for the root servers of the Domain Name System (DNS), and for various major CDNs, including Cloudflare‘s, for example. What’s more, many popular DNS resolvers are in fact multiple systems with a common IP address. Google’s 8.8.8.8 address routes to Google resolvers all over the world, for example.
Why put anycast nodes in the cloud?
At SIDN Labs, we often study the various aspects of anycast. We’re interested in how the technology behaves, how it can be optimised and how security can be improved (a detailed explanation of our research motivations is given in this background article on Tweakers). The expertise we gain is used for .nl and shared with the internet community for the benefit of the internet as a whole.
Against that backdrop, we have been considering how we could make a global anycast infrastructure more cost-effective and flexible. The reason being that the traditional approach of physically shipping hardware to locations around the world is expensive, time-consuming and inflexible. Adding a server in Singapore or moving one from Miami to Dallas is easier said than done.
We therefore decided to investigate the scope for using virtual servers and ‘bare metal’ rented from cloud vendors – in other words ‘Infrastructure as a Service‘ (IaaS). In recent years, the IaaS industry has grown enormously and matured, but we wanted to know whether IaaS vendors could offer facilities suitable for running vital core internet applications, such as a TLD’s name servers. That would require support for BGP, for example, including support for custom AS numbers and custom IPv4 and IPv6 address blocks.
Testbed set-up and management
With a view to answering the questions outlined above, we set up an anycast testbed, which now consists of twenty-two nodes distributed across sixteen locations worldwide (Figure 2). In some regions, particularly South America, Africa and parts of Asia (including China), it proved to be harder to find suitable vendors and locations. Many did not support use of custom IP address blocks, for example.
We are currently working with three vendors: Packet (now Equinix), Vultr and Heficed. It has been interesting to compare them, since they differ in various respects, including service features, pricing and support.
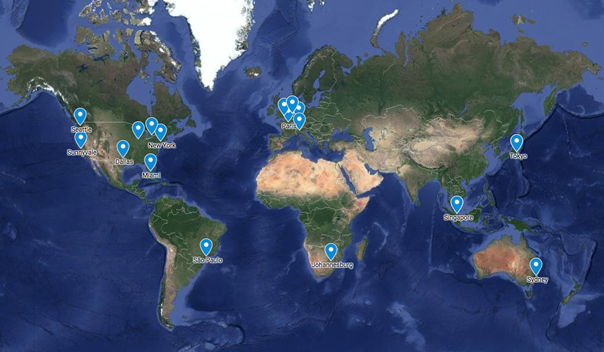
Figure 2: Locations of our anycast nodes.
The testbed serves a number of test domains, rather than the .nl zone itself, but we see it as prototype for a similar production set-up for the .nl domain. We envisage the production version functioning as a ‘flexible shell’ to complement the existing DNS infrastructure. The testbed servers are authoritative DNS servers that we use for measurement purposes. If, for example, we send a DNS query asking for the TXT record for dnstest.nl, we can easily see on the server side which anycast node in which region responds. By using RIPE Atlas and the NLNOG ring to fire off queries from locations all over the world, we can build up a complete picture of how our testbed works.
You can perform your own small-scale test, using this online tool, for example. From the response, you can see which anycast node has handled your query, which will depend on where you send it from. Our nodes are identified using airport codes: AMS for Amsterdam, JNB for Johannesburg, and so on. By doing this test, you can get a neat picture of how well the response times for example.nl’s anycast servers (anytest1) compare with the response times for the unicast servers (ex1 and ex2).
We set up the testbed so that we could centrally disconnect and reconnect nodes (or disable/re-enable BGP sessions) at will in order to study the effects. That capability was utilised to carry out a variety of tests. Our ultimate goal is to raise the abstraction level of anycast management by deploying intelligent measurement-based tools, such as BGP Tuner, ‘node recommenders’ and visual interfaces. That would enable operators to regulate their anycast networks on a smarter, more automated basis.
Attracting traffic
A testbed doesn’t receive any production traffic, of course. Yet, in order to gather representative information, we wanted the nodes to receive reasonably realistic traffic flows. Initially, therefore, we generated DNS traffic ourselves: from RIPE Atlas nodes; via the open resolvers that are available around the world, and so on. However, we soon decided that a better approach was needed: the arrangement wasn’t sufficiently scalable, and we were generating too little test traffic from too few locations.
Source 1: DNS over HTTPS
In the summer of 2020, when DNS over HTTPS (DoH) was attracting a lot of attention, we decided to extend our experimental DoH server by adding an anycast variant (anydoh.sidnlabs.nl) to the testbed. That drew DNS over HTTPS traffic to our testbed and enabled us to demonstrate that our approach could work for services of other types as well.
Source 2: traffic for botnet sinkholes
At SIDN Labs, we control a number of ‘ex-botnet’ domain names: names that malicious actors have previously registered and programmed into botnet software, such as the software for the Andromeda and Cutwail botnets. We use the names for research purposes and have them set up to point to a ‘sinkhole’ server. Interestingly, the domain names in question, such as ‘hzmksreiuojy.nl‘, continue to attract a reasonable amount of DNS and other traffic.
We arranged for that DNS traffic to go to the testbed as well, resulting in a good, continuous flow of DNS queries. Later we also added the DNS traffic for minimafia.nl – a domain name that had once been used as a torrent tracker, and continues to generate a significant traffic flow.
Source 3: NTP
Our biggest traffic inflow was secured by setting up our testbed to operate as part of the NTP pool, under the name ‘any.time.nl’. The pool consists of a large virtual cluster of NTP time servers that are consulted by clients all over the world. We set up a good stratum-2 NTP service on the testbed, then contacted the NTP pool’s administrators to make arrangements regarding the coverage and capacity of any.time.nl, so that an appropriate volume of client traffic would be directed to our servers.
This arrangement too yielded a good, continuous (and substantial) traffic flow. Although the flow consisted of NTP traffic, rather than DNS traffic, that did not matter in the context of our research into anycast behaviour and management. We were also able to simultaneously contribute to the improved global availability of public NTP services.
Addition of the NTP service meant that the testbed took on a more serious character, since we now fulfil NTP time requests from about eighty to ninety thousand globally distributed users a second. A significant proportion of the users are in China, where the NTP pool’s coverage isn’t as good and the average load per server is therefore proportionally higher than in regions with greater coverage, such as Europe.
The main implication of running a service that is in proper use is that we can’t casually disconnect nodes for tests. Instead, we have to reduce the service’s bandwidth settings on the NTP pool dashboard in order to reduce the traffic flow to the testbed before we do any experiments that could affect the NTP service. In most cases, however, no adjustments are needed, since the nodes that remain active during simple catchment experiments usually provide sufficient capacity to handle the NTP traffic. Indeed, that’s another of the benefits of anycast.
Improved understanding of catchments
One of the most significant things we have achieved with the testbed so far is to improve our insight into anycast catchments when nodes are operating in the cloud. A catchment is the geographical area whose traffic is routed to a particular anycast node. So, for example, users in the US might be routed to a node in New York, while European traffic is sent to Frankfurt. Each node therefore has its own catchment – the intention being, of course, to ensure that traffic is routed as efficiently as possible, rather than travelling half way round the world.
Figure 3 shows the catchment for our node in Sidney. The node takes traffic from Australia, New Zealand and other places that are located nearby in terms of network topology. However, a small amount of traffic from Singapore also reaches Sidney, even though we have two nodes in Singapore itself.
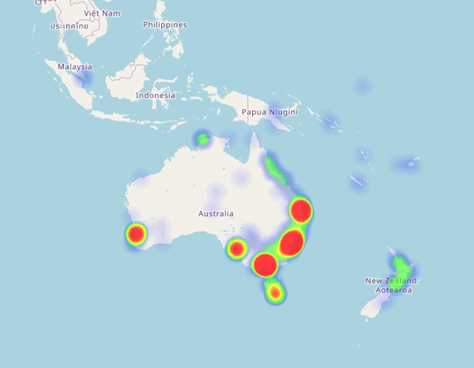
Figure 3: BGP catchment for the Sydney node.
BGP catchments are not always strongly localised. For example, the node in São Paulo (Brazil), gets quite a lot of traffic from Italy, despite the presence of a node in Milan (Figure 4).
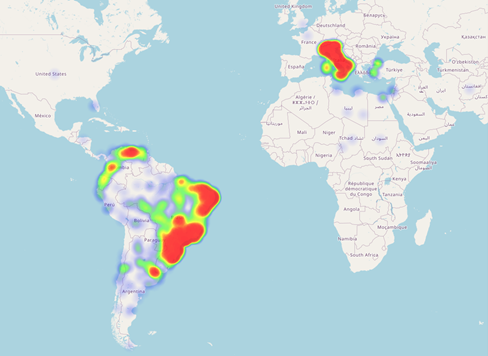
Figure 4: Less localised catchment for the São Paulo node.
It proved difficult to eliminate such issues, because BGP offers limited scope for making fine adjustments and distributing traffic without causing all traffic to suddenly switch. However, our catchment visualisations did provide us with a quick, clear overview of the situation. Having a good, continuous flow of DNS and NTP traffic (with the latter dominant) from all around the world was very helpful in that regard.
The animated GIFs above are taken from: https://downloads.sidnlabs.nl/anycast2020/screenshots/
Lessons learnt about running anycast in the cloud
First, we found significant differences amongst vendors in terms of customer connectivity provisions and billing. One variable that was particularly significant to us was whether the vendors made active use of internet exchanges, or took the easy option of purchasing IP transit from a small number of sources. Exchange use proved to facilitate good catchment localisation. We also observed differences in terms of the scope for BGP tuning, such as support for BGP communities and AS path prepending.
Another lesson we learnt was that a cloud-based model allows less control over node catchments, because a BGP session has to be set up with the cloud vendor. Our nodes were not therefore connected to the internet exchanges, where we would have been free to make whatever peering arrangements we wanted. Instead, we were dependent on the vendors’ connectivity, so our node catchments were determined by the vendors to a large extent.
Finally, we learnt that catchment tuning is difficult. That’s unfortunate, because it’s desirable that catchments are localised, and that implies tuning. Unfavourable routing, where traffic travels very large distances when there is a node ‘nearby’, should be eliminated wherever possible. To some extent, BGP ‘automatically’ minimises unfavourable routing. However, intervention is sometimes required, and in such cases one obviously wants the cloud vendor to offer appropriate support.
Conclusions and follow-up
A year on from our project’s start, we can reasonably say that it’s been a success. We were able to set up a relatively flexible and cost-effective global server infrastructure. Our experiments yielded a wealth of information and insight, which we are currently using to build a similar, flexible, production-quality shell to complement the .nl domain’s existing DNS infrastructure. We demonstrated that running a global anycast DNS service infrastructure in the cloud is affordable and flexible, but does present certain challenges. Our testbed has also made a significant contribution to improvement of the global public NTP infrastructure.
In due course, we would like to have a testbed that allows for capacity to be added or redistributed anywhere in the world at a few minutes’ notice, as the situation requires. We also plan to extend our anycast catchment research work in collaboration with the University of Twente. We’re already running the MAnycast² project in partnership with the university. Using special software called ‘Verfploeter‘, we can detect from our testbed how many other anycast environments there are around the world (figure 5). Our aim is to validate and enrich earlier measurements performed in the context of this research project and to contribute to improvement of the methodology. As always, we will be sharing our results with the research and operating communities.
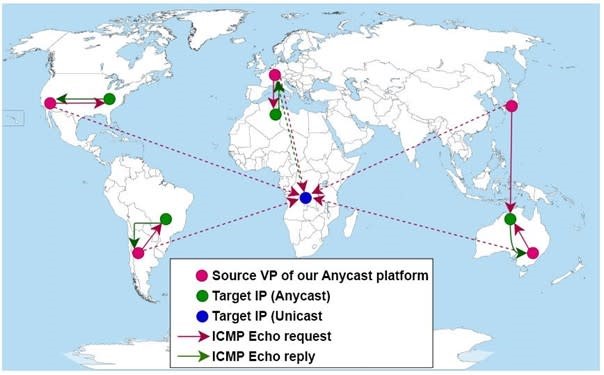
Figure 5: Functional principle of MAnycast².
This message is taken from SIDN Labs, read the entire blog here