
Test levert waardevolle informatie voor nieuwe productiewaardige flexibele schil rond onze anycast-infrastructuur.
Sinds begin 2020 draaien we bij SIDN Labs een BGP anycast testbed. Dit doen we, omdat we willen onderzoeken hoe een wereldwijde anycast-infrastructuur kosteneffectiever en flexibeler zou kunnen worden opgezet. Kosteneffectiever, door niet meer fysiek met servers over de wereld te slepen en flexibeler, om snel te kunnen inspringen op veranderende behoeftes. Ons uiteindelijke doel is het systeem naar productieniveau te tillen zodat het een ‘flexibele schil’ vormt rond onze bestaande geanycaste DNS-infrastructuur voor .nl. In deze blog geven we je een update over hoe het er nu, bijna een jaar later, voor staat.
Over anycast
Anycast is een beproefde methode om de weerbaarheid en de prestaties van internetinfrastructuren te verhogen. Het principe is simpel; door op meerdere plekken servers te plaatsen met hetzelfde IP-adres, verdeelt het routeringssysteem van het internet automatisch de verkeersbelasting over die servers. Dit zorgt voor een betere gebruikerservaring omdat responsetijden lager worden. Zo komt een gebruiker uit Nederland uit bij een server in Amsterdam, terwijl iemand uit Japan naar de server in Tokyo gerouteerd wordt. Anycast is ook gunstig bij piekbelastingen, zoals bij een DDoS-aanval. Een anycast-infrastructuur werkt dankzij het Border Gateway Protocol (BGP), het routeringsprotocol van het internet. BGP zorgt ervoor dat internetverkeer steeds de voordeligste (meestal de kortste) route volgt van A naar B (Figuur 1).
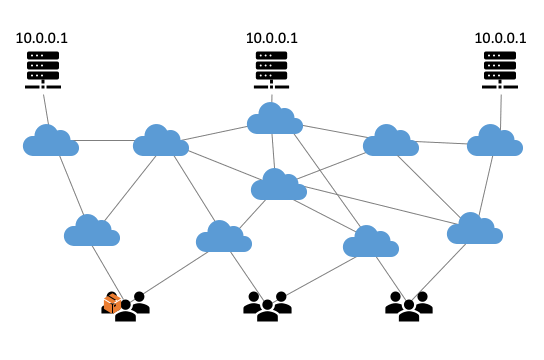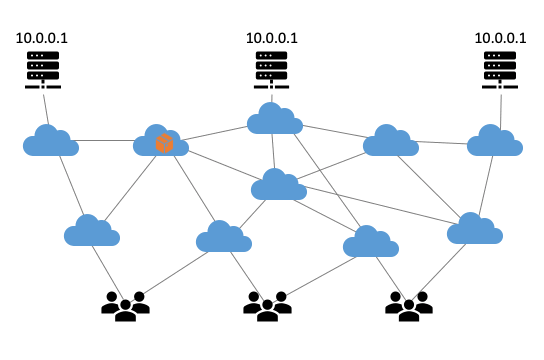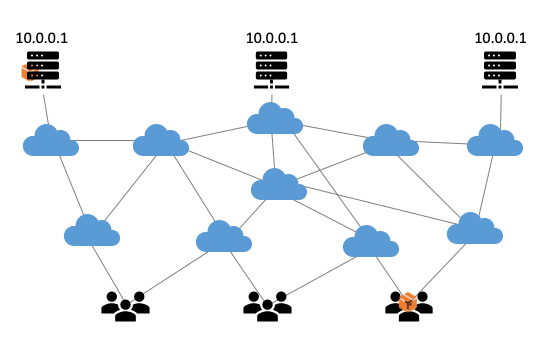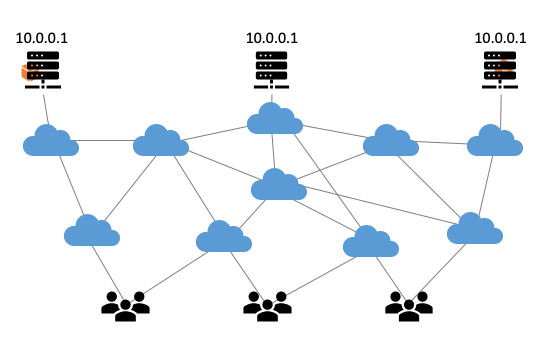
Figuur 1: De werking van anycast gevisualiseerd.
Anycast heeft zich in de praktijk bewezen en we zetten dit mechanisme dan ook zelf in voor de DNS-infrastructuur van .nl. We zijn hierin overigens niet uniek; allerlei andere partijen op het internet passen anycast toe, waaronder onze collega-registry’s, de rootservers van het Domain Name System (DNS) en allerlei grote CDN’s, zoals dat van Cloudflare. Ook bekende DNS-resolvers bestaan in feite uit vele systemen met hetzelfde IP-adres. Bij Google is dat 8.8.8.8 en staan de Google-resolvers verspreid over de hele wereld.
Waarom anycast-nodes in de cloud?
Bij SIDN Labs doen we geregeld onderzoek naar de verschillende aspecten van anycast. Want we zijn geïnteresseerd in hoe het zich gedraagt, hoe het kan worden geoptimaliseerd en beter kan worden beveiligd (een uitgebreidere uitleg van onze motieven vind je in dit achtergrondartikel op Tweakers). De expertise die we opdoen gebruiken we voor .nl en delen we daarnaast met de internetgemeenschap, zodat het hele internet er beter van wordt.
In het verlengde hiervan vroegen we ons af hoe we een wereldwijde anycast-infrastructuur kosteneffectiever en flexibeler in zouden kunnen zetten. De reden hiervoor is dat het traditionele verschepen van fysieke hardware naar locaties over de hele wereld kostbaar, tijdsintensief en inflexibel is. Even een server erbij in Singapore of toch maar liever eentje in Dallas in plaats van in Miami is sneller gezegd dan gedaan.
De aanpak die we bedachten was gebruik te maken van virtuele servers en ‘bare metal’ die we afnamen van cloudleveranciers. Dit staat ook bekend als ‘Infrastructure as a Service’ (IaaS). Deze bedrijfstak is de laatste jaren enorm gegroeid en volwassen geworden, maar we wilden graag weten of IaaS-leveranciers ook de faciliteiten bieden voor het draaien van belangrijke kerntoepassingen voor het internet, zoals de nameservers voor een topleveldomein. Dit betekent bijvoorbeeld dat deze leveranciers ondersteuning moeten bieden voor BGP, inclusief het ‘meebrengen’ van een eigen AS-nummer en eigen IPv4- en IPv6-blokken.
De inrichting en beheer van het testbed
Om deze vragen te beantwoorden richtten we een anycast-testbed in, dat inmiddels bestaat uit 22 nodes, verdeeld over 16 locaties wereldwijd (Figuur 2). Voor sommige werelddelen bleek het lastiger om een geschikte leverancier en locatie te vinden, bijvoorbeeld met ondersteuning voor het gebruik van eigen IP-adresblokken. Dat gold vooral voor Zuid-Amerika, Afrika en delen van Azië (waaronder China).
We werken op dit moment met 3 leveranciers: Packet (tegenwoordig Equinix), Vultr en Heficed. Het was interessant om ze onderling te vergelijken, aangezien ze in detail verschillen qua features, prijsstelling en support.
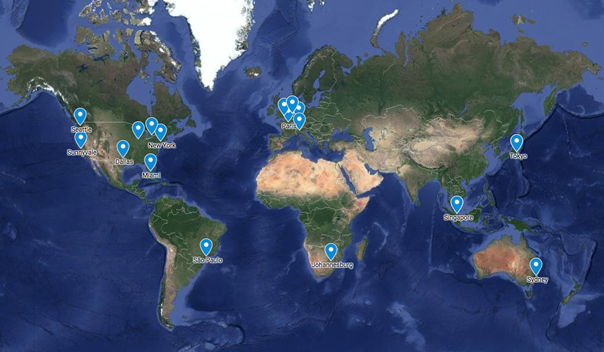
Figuur 2: De locaties van onze anycast nodes.
Het testbed draait een aantal testdomeinen en niet de .nl-zone zelf, maar we zien het wel als voorloper van een soortgelijke productie-setup voor het .nl-domein. Als ‘flexibele schil’ in aanvulling op de DNS-infrastructuur zoals die al draait. De servers in het testbed zijn autoritatieve DNS-servers die we gebruiken voor het uitvoeren van metingen. Ter illustratie; als we op ons testbed een DNS-verzoek afvuren voor het TXT-record van ‘dnstest.nl’, dan kunnen we ‘aan de achterkant’ eenvoudig zien welke anycast-node in welk werelddeel het antwoord heeft gegeven. Door deze testen wereldwijd uit te voeren met behulp van RIPE Atlas en de NLNOG-ring, krijgen we een compleet beeld van de werking van ons testbed.
Op kleinere schaal kun je dit zelf ook proberen via bijvoorbeeld deze online tool. Aan de antwoorden kun je zien welke anycast-node het antwoord geeft, afhankelijk vanaf waar je de vraag stelt. We gebruiken daarvoor vliegveld-codes. Dus AMS staat voor de node in Amsterdam, JNB voor Johannesburg, enz. En deze test laat bijvoorbeeld mooi zien hoeveel beter de responsetijden zijn van de anycast-servers van ‘example.nl’ (anytest1), in vergelijking met de unicast-servers (ex1 en ex2).
We richtten het testbed zo in dat we centraal, naar wens, nodes konden afkoppelen en weer aankoppelen (oftewel BGP-sessies uit- en weer aanzetten), om te zien wat daarvan de effecten waren. Op deze manier deden we allerhande tests. Het uiteindelijke doel is dat we het anycast-beheer naar een hoger abstractieniveau tillen, door intelligente meet-gebaseerde tools zoals de BGP Tuner, zogenaamde ‘node recommenders’ en visuele interfaces. Zo kunnen operators op een slimmere en meer geautomatiseerde manier het anycast-netwerk aanpassen.
Het aantrekken van verkeer
Aangezien het hier een testbed betreft, trok het geen productieverkeer aan. Toch was het voor het doen van goede metingen handig als er enigszins realistisch verkeer zou binnenkomen op de nodes. Aanvankelijk realiseerden we dit door zelf DNS-verkeer te genereren, vanaf bijvoorbeeld RIPE Atlas nodes of via open resolvers die wereldwijd te vinden zijn. Maar hierover waren we al snel minder enthousiast, onder meer omdat het onvoldoende schaalde en we te weinig testverkeer genereerden, vanaf te weinig plekken. Daarom gingen we op zoek naar iets beters.
Bron 1: DNS-over-HTTPS
Medio 2020, toen DNS-over-HTTPS (DoH) flink in de belangstelling stond, besloten we om onze experimentele DoH-server uit te breiden met een anycast-variant op het testbed, genaamd anydoh.sidnlabs.nl. Hiermee ontvingen we DNS-over-HTTPS-verkeer op ons testbed en toonden we aan dat onze aanpak ook kan werken voor andere soorten services.
Bron 2: verkeer voor botnet-sinkholes
Bij SIDN Labs hebben we een aantal zogenaamde botnet-domeinnamen geregistreerd, die kwaadwillenden in het verleden in hun botnet-software hebben geprogrammeerd, bijvoorbeeld in het Andromeda- of het Cutwail-botnet. We laten deze voor onderzoeksdoeleinden naar een zogenaamde sinkhole-server wijzen. Het gaat hier bijvoorbeeld om domeinnamen zoals ‘hzmksreiuojy.nl’, die opvallend genoeg nog steeds behoorlijk wat (DNS-)verkeer genereren.
We zorgden ervoor dat dit DNS-verkeer binnenkwam op het testbed. Dit leverde een mooie constante stroom DNS-verzoeken op. Later voegden we hier nog het DNS-verkeer aan toe van een domeinnaam die ooit in gebruik was als torrent-tracker. Ook deze domeinnaam (‘minimafia.nl’) genereert nog steeds behoorlijk wat DNS-verkeer.
Bron 3: NTP
Maar het meeste verkeer kwam binnen toen we besloten om ons testbed onder de naam ‘any.time.nl’, mee te laten draaien met het NTP-pool-project. Dat is een groot virtueel cluster van NTP-tijdservers waar wereldwijd veel clients gebruik van maken. We richten een goede stratum 2 NTP-service in op het testbed. We namen daarna contact op met de beheerders van de NTP-pool en stemden met hen af wat de dekking en capaciteit was van any.time.nl. Want afhankelijk hiervan bepaalt de pool hoeveel clients worden doorverbonden met deelnemende servers.
Ook dit leverde ons een mooie constante (en behoorlijk forse) verkeerstroom op. Weliswaar betreft dit NTP- en geen DNS-verkeer, maar voor ons onderzoek naar anycast-gedrag en -beheer maakt het protocol in deze geen verschil. Tegelijkertijd droegen we met any.time.nl bij aan het wereldwijd beter beschikbaar maken van publieke NTP-diensten.
Het testbed kreeg hiermee een serieuzer karakter. Immers, we serveren nu NTP-tijd aan ruim 80.000 tot 90.000 verschillende gebruikers per seconde, wereldwijd. Waarvan een aanzienlijk deel uit China, waar de NTP-pool minder goede dekking heeft en waar de gemiddelde belasting per server dus verhoudingsgewijs hoger is dan in regio’s met een veel hogere dekkingsgraad, zoals in Europa.
Het toevoegen van een dienst die echt gebruikt wordt betekent vooral dat we minder onbezonnen nodes kunnen afschakelen voor tests. In plaats daarvan verminderen we via het dashboard van de NTP-pool eerst de bandbreedte-instellingen, om daarmee verkeer van het testbed te halen, voordat we experimenten gaan doen die de NTP-service raken. Maar meestal hoeft dat niet en is het zo dat er in het testbed voldoende capaciteit overblijft om alsnog het NTP-verkeer netjes te kunnen afhandelen op de resterende nodes, wanneer we eenvoudige catchment-experimenten draaien. Nog een mooi voordeel van anycast.
Meer inzicht in catchments
Een van onze belangrijkste resultaten tot nu toe is dat het testbed ons meer inzicht heeft gegeven in anycast-catchments als we nodes bij cloudproviders draaien. Onder een catchment verstaan we het geografische gebied vanwaar verkeer naar een bepaalde anycast-node wordt gerouteerd. Bijvoorbeeld dat gebruikers in de VS terechtkomen op een node in New York, terwijl Europese gebruikers uitkomen in Frankfurt. Elke node heeft dus zijn eigen catchment en uiteraard is het doel om verkeer zo efficiënt mogelijk naar een anycast-node te sturen, in plaats van de halve wereld over te laten gaan.
Figuur 3 laat de catchment zien voor onze node in Sidney. De node trekt netjes het verkeer aan vanuit Australië, Nieuw-Zeeland en andere locaties die netwerktopologisch in de buurt zijn. Toch komt er ook nog een klein beetje verkeer uit Singapore, terwijl we daar ook 2 nodes hebben staan.
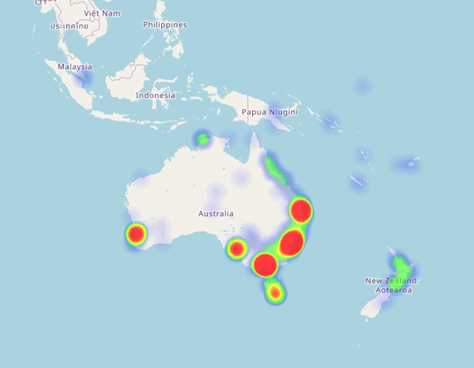
Figuur 3: Lokale BGP-catchment voor de node in Sydney.
Soms is de BGP catchment minder lokaal. De node in São Paulo (Brazilië), trekt bijvoorbeeld vrij veel verkeer aan uit Italië, terwijl we in Milaan wel degelijk ook een node hebben staan (Figuur 4).
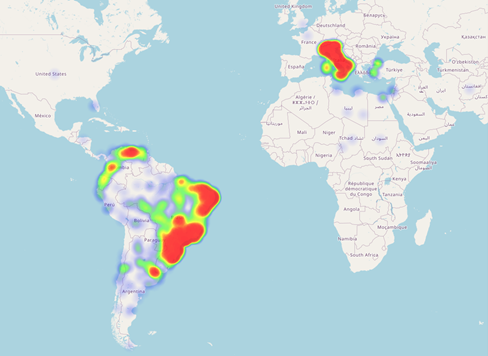
Figuur 4: Minder lokaal catchment voor de node in São Paulo.
Het bleek lastig om dit helemaal goed te tunen, omdat dat het met BGP niet goed mogelijk om heel fijnmazig bij te sturen en te doseren, zonder het punt te bereiken dat ineens alle verkeer omklapt. Met onze catchment-visualisaties brachten we dit echter snel en overzichtelijk in beeld. Het feit dat we een mooie constante hoeveelheid DNS- en (met name) NTP-verkeer vanuit de hele wereld aantrokken was hierbij van groot nut.
Bovenstaande geanimeerde gif’s komen van: https://downloads.sidnlabs.nl/anycast2020/screenshots/.
Geleerde lessen met anycast en cloud
Allereerst constateerden we verschillen tussen de leveranciers in de wijze waarop ze connectiviteit voor hun klanten hebben geregeld en hoe ze dit doorberekenen. Zo maakt het vooral voor onze use case uit of de leveranciers zelf actief zijn op internet-exchanges, of dat ze iets gemakzuchtiger zijn en alleen maar bij een paar partijen IP-transit inkopen. In dat eerste geval is de kans op een lokalere catchment groter. Maar ook constateerden we verschillen qua mogelijkheden die leveranciers bieden aan klanten op het vlak van BGP-tuning, zoals ondersteuning voor BGP communities en AS-path prepending.
We leerden ook dat we met een cloud-model minder grip hebben op catchments, omdat we een BGP-sessie opzetten met de cloudleverancier. Onze nodes zijn zodoende niet aangesloten op internet-exchanges, waar we naar wens peering-afspraken zouden kunnen maken. In plaats daarvan zijn we afhankelijke van goede connectiviteit van onze leveranciers, die weer in hoge mate de catchment op onze nodes bepaalt.
Tot slot leerden we dat het tunen van catchments lastig is. Tuning is echter wel belangrijk, want we streven naar een zo lokaal mogelijke catchment. We hebben het liefst zo min mogelijk ‘ongunstige routering’, waarbij het verkeer de halve wereld over gaat terwijl er ‘in de buurt’ ook een node is. Voor een deel ging dit, dankzij BGP, al ‘vanzelf’ goed. Maar soms was ingrijpen nodig en dan is het fijn als de cloudleverancier dat ondersteunt.
Conclusie en toekomstig werk
Ons project startte een jaar geleden en we durven wel te stellen dat het project succesvol is. Inderdaad konden we relatief flexibel en kosteneffectief servers uitrollen over de wereld. Onze experimenten leverden een schat aan informatie en kennis op, die we momenteel weer inzetten bij de bouw van een vergelijkbare flexibele schil van productiekwaliteit als aanvulling op onze bestaande DNS-infrastructuur voor het .nl-domein. We toonden aan dat het ‘in de cloud’ draaien van een wereldwijde anycast-infrastructuur voor DNS-services betaalbaar en flexibel is, maar dat het ook de nodige uitdagingen kent. Ook dragen we met ons testbed inmiddels significant bij aan een betere wereldwijde publieke NTP-infrastructuur.
Voor de toekomst willen we toe naar een testbed waarbij we binnen enkele minuten overal ter wereld naar wens capaciteit kunnen bijschakelen of kunnen verschuiven, als de situatie daarom vraagt. Ook gaan we ons onderzoek op het gebied van anycast catchments samen met de Universiteit Twente verder uitbreiden. Op dit moment werken we met hen aan het project MAnycast². Met behulp van speciale software, met de opmerkelijke naam ‘Verfploeter’, detecteren we vanuit ons testbed hoeveel andere anycast-omgevingen er wereldwijd zijn (figuur 5). Ons doel is om eerdere metingen in het kader van ditzelfde onderzoek te valideren en te verrijken en bij te dragen aan de verbetering van de methodologie. Onze resultaten delen we zoals altijd met de onderzoeks- en operationele community’s.
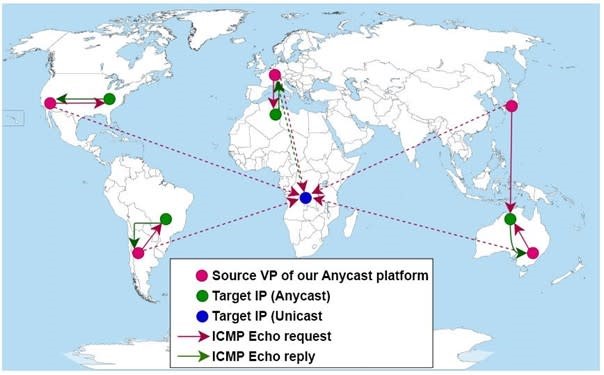
Figuur 5: Het werkingsprincipe van MAnycast².
Deze blog is overgenomen van SIDN Labs. Lees het artikel hier.